Removals Tool یکی از مهم ترین بخش های Google Search Console است که می توانید با استفاده از آن، هر آدرسی از سایت خود را در صورت نیاز به طور موقت از ایندکس گوگل حذف کرده و یا نحوه نمایش آن را تغییر دهید. در این قسمت از آموزش سرچ کنسول گوگل، به بررسی این ابزار و آموزش استفاده از آن می پردازیم.
برای استفاده از Removals Tool، وارد سرچ کنسول سایت خود شده و در منو سمت چپ زیر بخش Indexing بر روی گزینه Removals کلیک کنید.
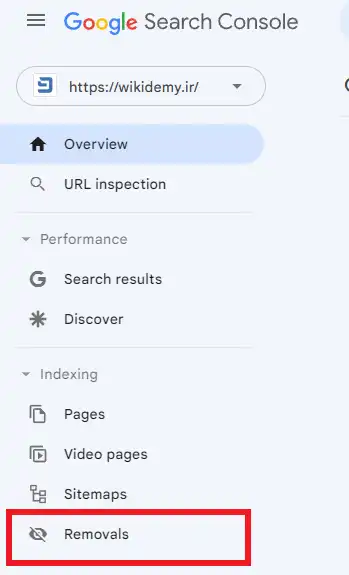
در این قسمت با سه بخش Temporary Removals، Outdated Content، و SafeSearch Filtering رو به رو خواهید شد.

بخش Temporary Removals
در این بخش می توانید در صورت نیاز، هر صفحه ای از سایت خود را به طور موقت از SERP کاربران حذف کرده و یا کش آن را تا کراول بعدی گوگل حذف نمایید.
برای استفاده از این بخش، روی گزینه New Request کلیک کنید. پس از کلیک، با دو گزینه Temporary Remove URLs و Clear Cache URL رو به رو خواهید شد.
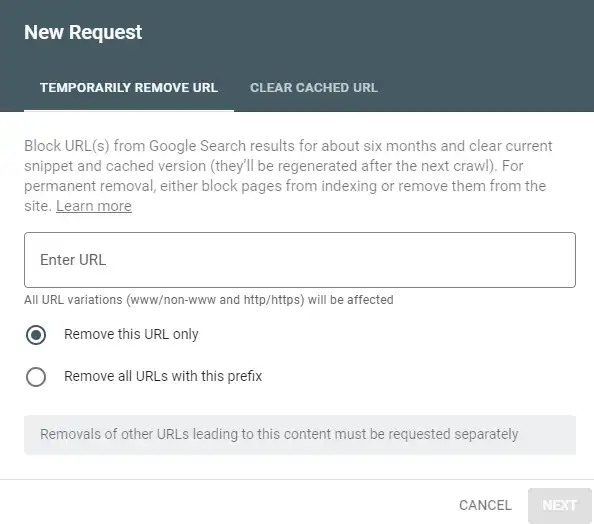
Temporary Remove URLs
از آن جایی که Temporary به معنای موقت می باشد، هر URL تهایتا برای 6 ماه از دید کاربران پنهان خواهد شد و پس از مجدد به آن ها نمایش داده می شود. از این رو، اگر قصد حذف دائمی یک صفحه را از سایت خود دارید، باید از پلاگین سئو وردپرس سایت خود استفاده کرده و درخواست 410 برای گوگل صادر کنید. به هیچ عنوان از فایل robots.txt برای این کار استفاده نکنید.
پس از وارد کردن ادرس سایت، باید یکی از دو گزینه های زیر ان را انتخاب نمایید:
- گزینه Remove this URL: در صورت انتخاب گزینه، تنها URL انتخاب شده به طور موقت حذف می شود.
- گزینه Remove all URLs with this prefix: در صورت انتخاب این گزینه، تمامی ساب فولدرهای آدرس وارد شده نیز به طور موقت حذف خواهند شد.
پس از پایان 6 ماه، صفحه شما پیش از نمایش مجدد در SERP، کراول شده و با محتوای حاضر در آن رتبه بندی خواهد شد.
در صورت نیاز به کنسل کردن درخواست خود، می توانید وارد بخش Requests شده و درخواست خود را پیدا کنید. سپس روی منو آن کلیک کرده و Cancel را بزنید.
Clear Cache URLs
این بخش برای محتواها صفحاتی است که شامل تغییرات فراوان چشمگیری شده و یا در آدرس صفحه از صفر بازسازی شده اند. در این حالت، تمام کش صفحه و Snippet های قدیمی آن از گوگل حذف شده و تا زمان خزش مجدد صفحه، نمایش داده نخواهند شد.
دقت داشته باشد که اگر صفحه شما فقط یک آپدیت ساده محتوایی داشته است، بهتر است که از این بخش استفاده نکرده و در قسمت URL Inspection در خواست ایندکس مجدد صفحه را بدهید.
بخش Outdated Content
اگر صفحه ای از سایت خود را آپدیت کرده، اطلاعات حیاتی از آن حذف و یا به آن اضافه کرده اید و این صفحه همچنان با اطلاعات قدیمی خود در SERP نمایش داده می شود، باید در این صفحه درخواست خود را ثبت کنید.
دقت داشته باشید که تنها در صورتی از این بخش اسنفاده کنید که با وجود درخواست ایندکس مجدد، پس از گذشت حداقل دو هفته، با اطلاعات قبلی خود نمایش داده شود.
برای استفاده از این بخش، روی منو آن کلیک کرده و گزینه مورد نظر خود را انتخاب نمایید. در نظر داشته باشید که هر درخواست باید به طور جداگانه ثبت شود.

پس از ثبت درخواست، به حالت pending در خواهد آمد. به طور مرتب در خواست خود را چک نمایید. اگر درخواست شما با موفقیت قبول شود، تغییرات درخواست شده اعمال خواهند شد. در در صورت رد شدن درخواست، علت آن نمایش داده خواهد شد.
بخش SafeSearch Filtering
بخش SafeSearch Filtering برای مشخص کردن بخش هایی از سایت است که ممکن است محتوایی نامناسب برای افراد زیر 18 سال داشته و تنها مناسب بزرگسالان باشد. اگر درخواستی برای SafeSearch کردن یک صفحه یا محتوایی برای گوگل فرستاده شده و تایید شود، این صفحه یا محتوا برچسب محتوای مخصوص بزرگسالان می خورد.
برای این کار، بخش SafeSearch Filtering را باز کرده و درخواست خود را ثبت کنید. پس از ثبت، این درخواست در مرحله pending قرار می گیرد.
اکنون می توانید از بخش Removals Tool سرچ کنسول گوگل استفاده کرده و صفحات مورد نیاز را از SERP به طور موقت حذف کرده و یا تغییر دهید. دقت داشته باشید که از بخش های مختلف این ابزار به درستی استفاده نمایید.